YARN Introduction
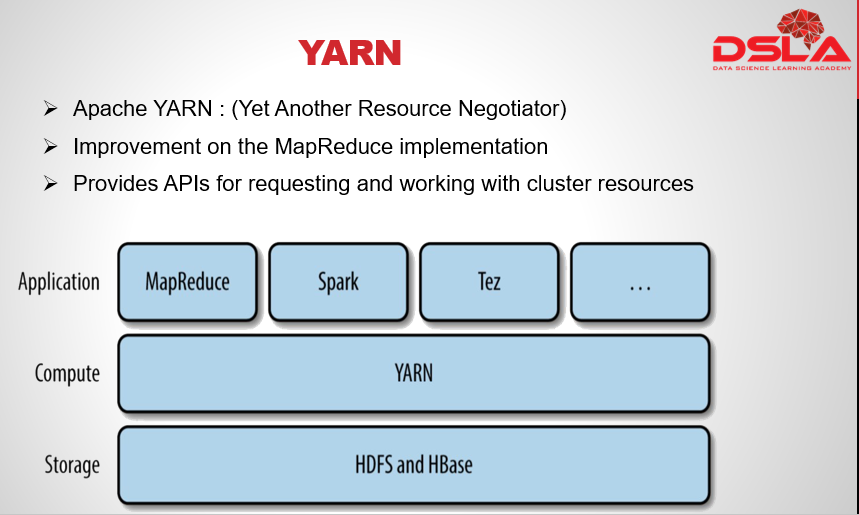
Apache YARN introduction: it is short for Yet Another Resource Negotiator. As the name indicates it is a Hadoop’s cluster resource management system.
YARN was introduced in Hadoop version 2 to improve the MapReduce implementation, but it is general enough to support other distributed computing paradigms as well.
Yarn allows different data processing engines like graph processing, interactive processing, stream processing as well as batch processing to run and process data stored in HDFS .
Apart from resource management, Yarn also does job Scheduling. Yarn extends the power of Hadoop to other evolving technologies, so they can take the advantages of HDFS which is a most reliable and popular storage system on the planet and economic cluster. (CONTINUED NEXT)
YARN provides APIs for requesting and working with cluster resources, but these APIs are not typically used directly by user code. Instead, users use higher-level APIs provided by distributed computing frameworks, which themselves are built on YARN and hide the resource management details from the user.
shown in the figure are some distributed computing frameworks – (MapReduce, Spark, and so on), here they are running as YARN applications on the cluster compute layer i.e. (YARN) and the cluster storage layer i.e. (HDFS and HBase).
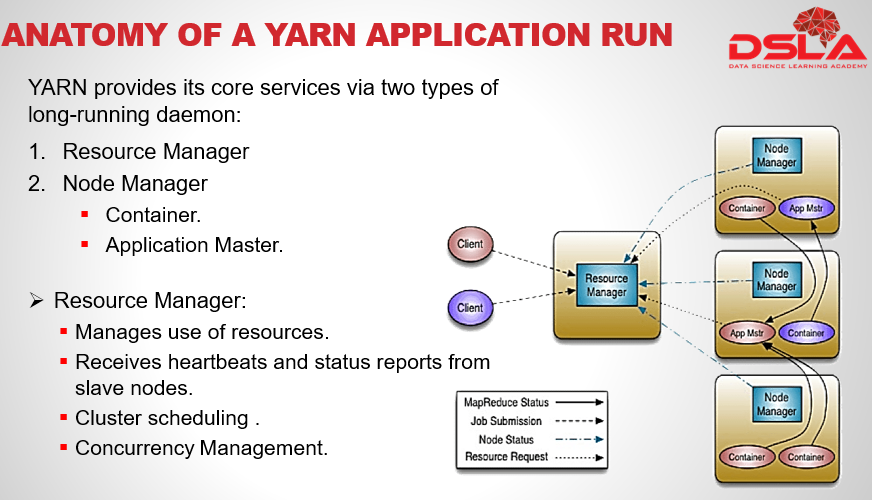
YARN provides its core services via two types of long-running daemon:
Resource Manager and Node Manager…
Containers and application master runs on Node manager
Let’s discuss each term in more details
And we are starting with resource manager…
The Resource Manager is the YARN master node daemon which is responsible for granting resources to applications in the form of containers, which are predefined compute units consisting of memory and virtual CPU cores.
The Resource Manager receives heartbeats and status reports from slave nodes in the YARN cluster to monitor availability of cluster resources. The Resource Manager is also responsible for cluster scheduling and managing concurrency. which would be discussed in more detail later.

Node manager runs on all the nodes and is responsible for launching and managing containers running on cluster nodes.
The NodeManager process also monitors consumption and reports application progress, status and health back to the resource manager
Containers execute tasks as specified by the Application Master. It executes an application-specific process with a constrained set of resources (memory, CPU, and so on). The YARN containers running on NodeManagers orchestrate processing stages and run tasks for distributed applications.
The ApplicationMaster is a process running on a NodeManager allocated by the ResourceManager for an application.The ApplicationsManager is responsible for accepting job-submissions, negotiating the first container & appropriate resource for executing the application. ApplicationMaster’s responsibilities includes services for restarting the ApplicationMaster on failure on another container.
It also has the responsibility of , tracking their status and monitoring for progress
Next we will see the steps to run an YARN application
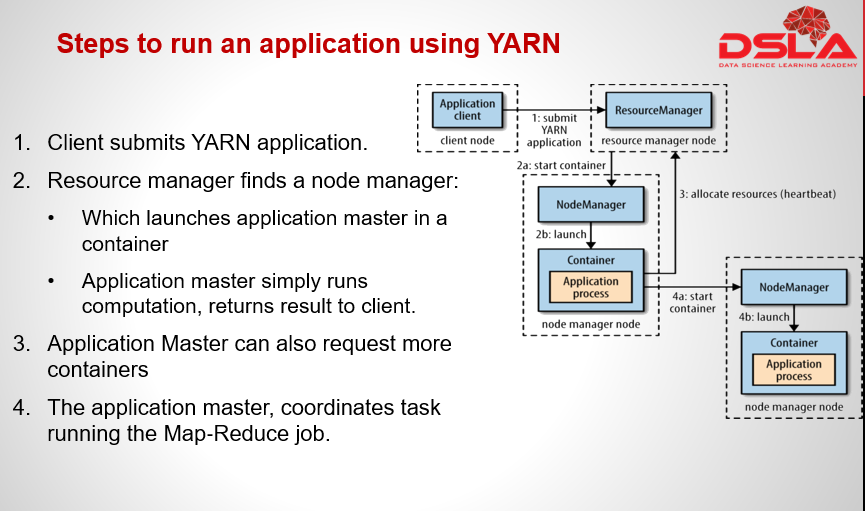
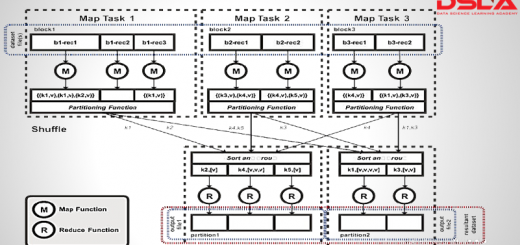
This figure illustrates how YARN runs an application. To run an application on YARN, a client contacts the resource manager and asks it to run an application master process as shown in figure as step 1. The resource manager then finds a node manager that can launch the application master in a container as u can see in steps 2a and 2b. Precisely what the application master does once it is running depends on the application :- It could simply run a computation in the container it is running in and return the result to the client Or it could request more containers from the resource managers as shown in step 3, and use them to run a distributed computation as you can see in steps 4a and 4b. The application master and the MapReduce tasks run in containers that are scheduled by the resource manager and managed by the node managers. Notice from Figure that YARN itself does not provide any way for the parts of the application (client, master, process) to communicate with one another.Most nontrivial YARN applications use some form of remote communication (such as Hadoop’s RPC layer) to pass status updates and results back to the client, but these are specific to the application.

High Availability (HA) can be configured and deployed for the Resource Manager process in YARN clusters. If HA is not enabled for the Resource Manager, the ResourceManager becomes a single point of failure (SPOF) for YARN, much like the NameNode is a SPOF for HDFS.
ResourceManager High Availability is realized through an Active/Standby architecture – at any point of time, one of the ResourceManager is Active, and one or more RMs are in Standby mode waiting to take over should anything happen to the Active one. The trigger to transition-to-active comes from either the admin (through CLI) or through the integrated failover-controller when automatic-failover is enabled.
Failover can be done by auto/manual:-
Manual transitions and failover:When automatic failover is not enabled, admins have to manually transition one of the ResourceManager to Active. To failover from one RM to the other, they are expected to first transition the Active-RM to Standby and transition a Standby-RM to Active. All this can be done using the “yarn rmadmin” CLI.
Automatic failover: The RMs have an option to embed the Zookeeper-based Active Standby Elector to decide which RM should be the Active. When the Active goes down or becomes unresponsive, another RM is automatically elected to be the Active which then takes over. Note that, there is no need to run a separate ZooKeeper daemon as is the case for HDFS because ActiveStandbyElector embedded in RMs acts as a failure detector too.

YARN has a flexible model for making resource requests. A request for a set of containers can express the amount of computer resources required for each container (memory and CPU), as well as locality constraints for the containers in that request.
Requests can also be handled by priority.
Locality is critical in ensuring that distributed data processing algorithms use the cluster bandwidth efficiently, so YARN allows an application to specify locality constraints for the containers it is requesting. Locality constraints can be used to request a container on a specific node or rack, or anywhere on the cluster. If the request is successful, the requested containers are granted.
Sometimes the locality constraint cannot be met, then either no allocation is made or, optionally, the constraint can be loosened. For example, if a specific node was requested but it is not possible to start a container on it (because other containers are running on it), then YARN will try to start a container on a node in the same rack, or, if that’s not possible, then on any node in the cluster.
A YARN application can make resource requests at any time while it is running. For example, an application can make all of its requests up front, or it can take a more dynamic approach.