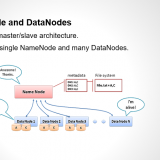
Name Node and Data Node
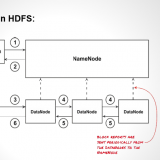
HDFS works upon a master-slave architecture, where It consists of a single NameNode, referred as master node and many DataNodes, referred as slave nodes. Master node consists of all the meta information of the data and helps datanode to carry out the operation required.
First let’s see the Namenode, this is the Master node of HDFS which Governs the distributed filesystem. Its most important function is management of the filesystem’s metadata. The HDFS metadata is basically a filesystem catalog, which contains all the directory, file objects and their related properties. NameNode is used to service the queries of the client. As a note, do remember that, During the NameNode startup process and recovery process, the NameNode is placed into safe mode. During this Safe mode, HDFS allows only read operation.
The NameNode’s metadata is perhaps the single most critical component in the HDFS architecture. Without it, the filesystem is not accessible, usable, or even recoverable. The NameNode’s metadata contains the critical link between blocks stored on each of the DataNodes and their context within files and directories in the Hadoop virtual filesystem. The metadata persists in resident memory on the NameNode to facilitate fast lookup operations for clients, predominantly read and write operations. Think of the metadata as a giant lookup table, which includes HDFS blocks, the HDFS object (file or directory) they are associated with, and their sequence within the file, as well as ACLs and ownership for the object and block checksums for integrity. There are also disk images of the metadata, including a snapshot to ensure durability and crash consistency, just like a relational database.
NameNode is the most important segment of the file architecture, as without the namenode, the filesystem cannot be used. In fact, if the machine running the namenode were obliterated, all the files on the filesystem would be lost since there would be no way of knowing how to reconstruct the files from the blocks on the datanodes. Hence, to put it simply, if namenode is down. HDFS is down. For this reason, it is important to make the namenode resilient to failure, and Hadoop provides two mechanisms for this.
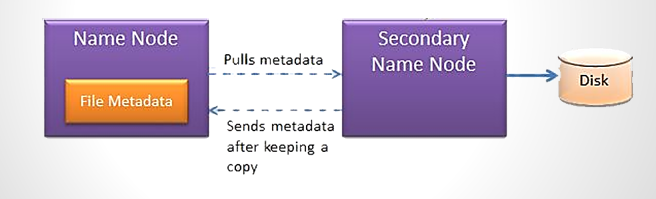
First, take backup of the files, that forms the persistent state of the filesystem metadata, to multiple location. Usually its configured to write to a local disk as well as to a NFS mount. Writes done here are synchronous and atomic.
2nd method to ensure resilience is, by using Secondary namenode. Its main role is to periodically merge the namespace image with the edit log, to prevent the edit log from becoming too large. Also, it runs on a separate machine as it requires the same amount of memory or CPU as the namenode. The duplicate copies of the namespace are preserved here in the event of namenode failure. The usual course of action, in this scenario, is to copy the NameNode’s metadata files that are on NFS to the secondary namenode and run it as the new primary. Do note: that The Secondary NameNode is not a high availability (HA) solution as the Secondary NameNode is not a hot standby for the NameNode, meaning, the state of the secondary namenode lags that of the primary.
Datanodes are known to be the workhorses of the filesystem. They are responsible for managing local volumes and storage. Blocks are stored on local volumes, on the hosts running the DataNode daemon. Checksums are calculated upon ingestion of data into the HDFS and are kept within the blocks. Additionally, The DataNode recalculates and compares these checksums periodically and reports mismatches to the NameNode. Also, heartbeats and Block reports are sent periodically to namenode, this helps NameNode in maintaining an inventory of blocks stored on the DataNodes. This inventory is then used to populate and maintain the NameNode’s metadata. DataNodes are also responsible for participating in the block replication pipeline which we have seen previously.
As a note do remember, that the datanode does not have any knowledge of how the blocks are related to files and directories in the HDFS filesystem. This relationship is held only in the NameNode’s metadata. A common misconception is that since it’s the DataNodes where all the data is stored, in a HDFS filesystem, they can also be used to reconstruct the filesystem, if the NameNode’s metadata was lost. This is not the case.