MapReduce Introduction

To begin, lets start with the most basic question of what is hadoops Mapreduce? MapReduce is a Simple programming model for data processing. MapReduce is an inherently parallel processing unit. Which essentially consists of 2 phases – Map and Reduce. These 2 are the main units of this programming. It also consists of shuffle, sort and partitioner phases.The Input, the output, and the intermediate results required in MapReduce are represented in the form of key-value pairs.Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data in-parallel on large of commodity hardware in a reliable, fault-tolerant manner.
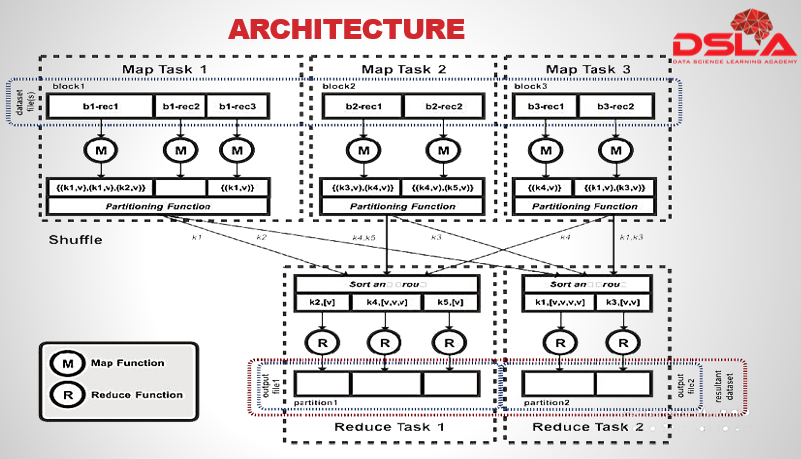
MapReduce, the programming model (or programming abstraction), was inspired by the map and reduce primitives in Lisp and other functional programming languages. MapReduce includes two developer-implemented processing phases, the Map phase and the Reduce phase, along with a Shuffle-and-Sort phase, which is implemented by the processing framework. The figure describes the overall MapReduce process. This diagram you see here is an adaptation of the diagram provided in the original Google MapReduce whitepaper.
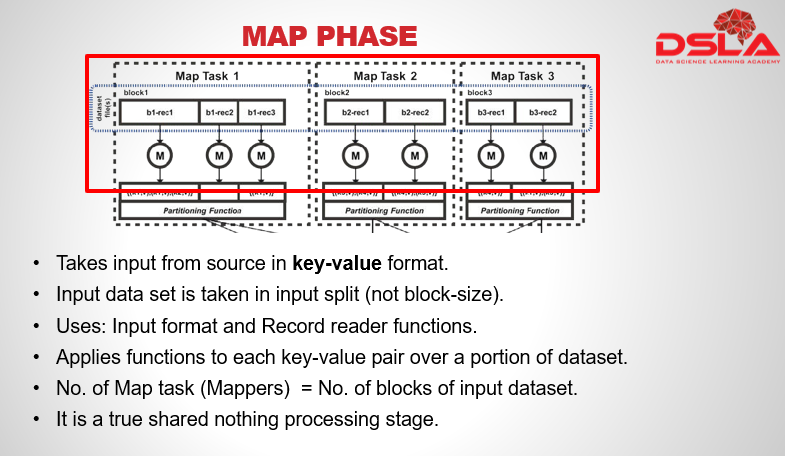
The Map phase is the initial phase of processing in which we input the dataset from source for processing. The Map phase uses input format and record reader functions in its implementation to derive records in the form of key-value pairs for the input data.
The Map phase then applies a function or functions to each key-value pair over a portion of the dataset. If there were n blocks of data in the input dataset, there would be n Map tasks, also referred to as Mappers. Do note, In reality, there may be more Map task attempts, as a task may fail due to node failure. The Map phase is purposely designed not to share state between processes; in other words, it is a true shared nothing processing stage.After completing the mapper task, the program needs to output its results.
Each map task has a circular memory buffer that it writes the output to. Default size of this buffer is 100mb)
On reaching buffer threshold, contents are spilled to disk.Spills are written in round-robin fashion.This output is considered to be an intermediate output. Hence are usually stored on the local system, instead of hdfs, to avoid data redundancy, caused by data replication. This output is usually absorbed by the reducer phase. The map() functions are valid as long as the function can be executed against a record contained in a portion of the dataset.

The mask task are also referred to as Mappers. Each mapper consists of one or more Map() function. Map() accepts one key-value pair and emits zero or more key-value pairs
The map() function is described in pseudo-code as follows:
map (keyin, valuein) -> list (intermediate_key, intermediate_value)
The list refers to the output from a map() function producing a list of outputs, with a list length of n output key-value pairs (where n could also be zero).Common map() functions include filtering of specific keys, such as filtering log messages if you only wanted to count or analyze ERROR log messages. Another example of a map() function would be to manipulate values, such as a map() function that converts a text value to lowercase.