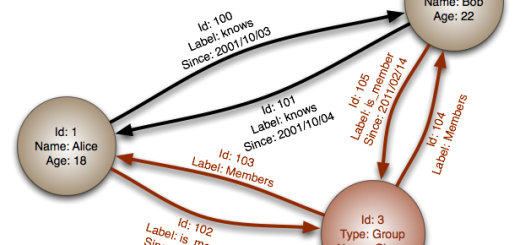
The Graph Database Model
The Graph Database Model For too long, relational database management has been the de facto standard for most of us looking to store data and retrieve the different values as and when desired. However,...
Transforming Business
The Graph Database Model For too long, relational database management has been the de facto standard for most of us looking to store data and retrieve the different values as and when desired. However,...
The Gremlin Graph Traversal Machine and Language Apache TinkerPop ™ is a graph computing framework for both graph databases (OLTP) and graph analytic systems (OLAP). Gremlin is the graph traversal language of Apache TinkerPop....
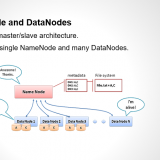
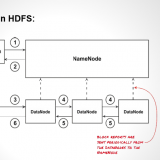
History Of Hadoop and its Comparison to Other Systems Hadoop isn’t the first distributed system for data storage and analysis, but it has some unique properties that set it apart from other systems and...
What is Hadoop ? what is Hadoop ? Hadoop is a complete eco-system of open source framework from Apache . It is used to store, process and analyze data which are very huge in...
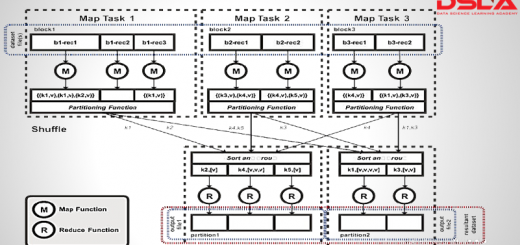
To begin, lets start with the most basic question of what is hadoops Mapreduce? MapReduce is a Simple programming model for data processing. MapReduce is an inherently parallel processing unit. Which essentially consists of...
In an ideal world, the requests that a YARN application makes would be granted immediately. In the real world, however, resources are limited, and on a busy cluster, an application will often need to...
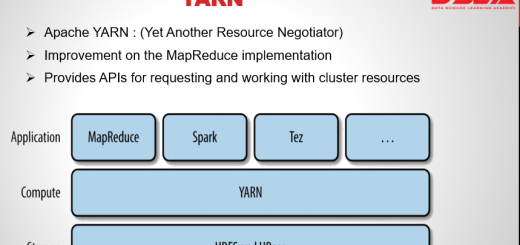
Major Difference between map reduce 1 and mapreduce2 i.e YARN. In MapReduce 1, there are two types of daemon that control the job execution process: a jobtracker and one or more tasktrackers. The jobtracker...
Apache YARN introduction: it is short for Yet Another Resource Negotiator. As the name indicates it is a Hadoop’s cluster resource management system. YARN was introduced in Hadoop version 2 to improve the MapReduce...
Hadoop has an abstract notion of filesystems, of which HDFS is just one implementation. First we see local, now it’s a filesystem for a locally connected disk with client-side checksums. Then hdfs i.e. Hadoop’s...

Analytics Translator / Artificial Intelligence / Big Data / Data Science
12 Sep, 2018