Introduction to HDFS
Hadoop Filesystem is called “Hadoop Distributed File System”. Files which are massive in size are divided into sections and stored in separate machines. The Filesystem that manages this network is called a Distributed Filesystem. Hdfs is very much capable of storing huge amount of data, i.e. not just gigabytes and terabytes, but peta and even exabytes of data. HDFS is often referred to as a ‘worm’ filesystem i.e write once, read many. Hadoop does Not.! require an expensive or highly reliable hardware. It is designed to run on clusters of commodity hardware, with built-in features that make it highly reliable and fault tolerant. This is because HDFS is designed to carry on working without a noticeable interruption to the user in case of the failure of any node.
As a note, do keep in mind that there are areas where HDFS would not be a good fit. For example, when low latency Data access is needed. HDFS is optimized for delivering a high through-put of data, and this may be at the expense of latency.
Secondly Hadoop is highly efficient in managing a small no. of large sized files, but not a large no. of small sized files.
Also, HDFS is not suitable for multiple edits and arbitrary file modifications as it only allows ‘append’ actions and can only be written by a single user.
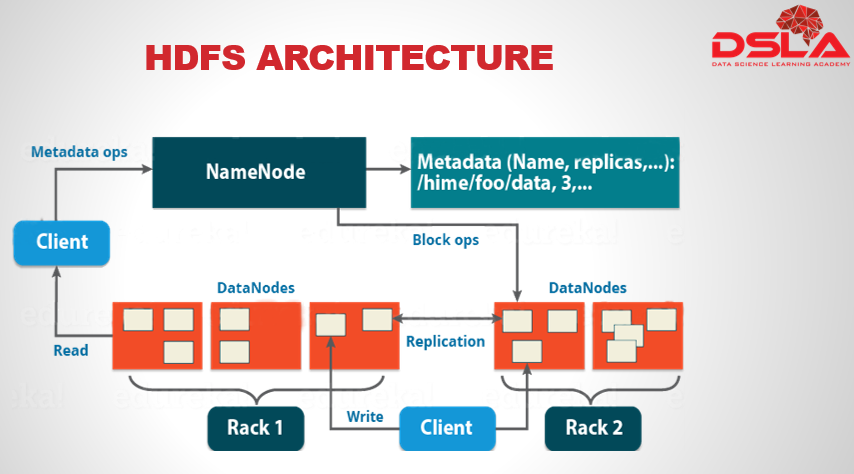
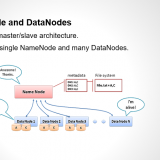
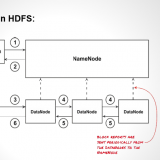
This here is the complete architecture of HDFS. From this architecture you can easily figure out the main components of HDFS, which are: Namenode and Datanode. All the major operations, takes place within these 2 sectors. But, apart from these, we have other very crucial components that comes together to form HDFS. Later, we would see, more details of each HDFS component.
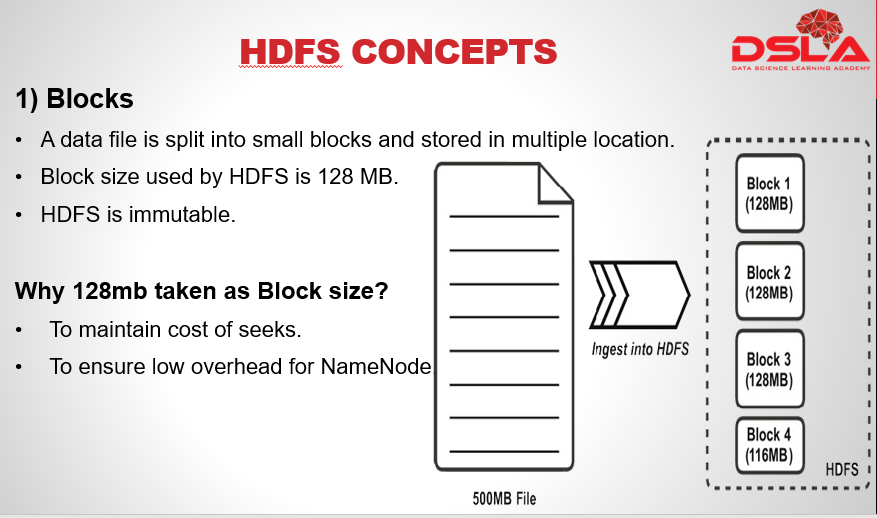
HDFS is a virtual filesystem, meaning, that it appears as a single system, but, underneath it, the files are split into blocks of fixed size upon ingestion into the HDFS. And if possible, the data blocks are stored on different datanodes, depending upon the size of the cluster. The default block size within HDFS is currently 128 MB. Another important property of HDFS is immutability. Immutability refers to the inability to update data after it is committed to the filesystem. This is ensured by “write once, read many” functionality also known as worm.
As for the question on why 128 MB is taken as the Block size?
The answer is that, this size is appropriate in maintaining the cost of seeks. For a large block of data, the cost of seeks, i.e. the time taken for seeks would be significantly lower than the time taken to transfer the dataset. secondly this size also ensures low overhead onNameNode, as all the division of a block, along with its meta properties needs to be registered with namenode.
In our adajcent figure we see a single file of 500mb in size split into fixed sized blocks upon ingestion to HDFS. Where 3 of them is 128mb and last is the smaller block with remaining content. Do note: that the block with smaller content would only occupy the required space and not the whole 128mb.