What is Apache Spark?
Apache Spark is a powerful open source processing engine, with a cluster computing framework.

Spark is designed in such a way to ensure lightening fast data processing of large datasets. this includes Batch processing and interactive queries on Huge amount of data. Real time analysis of streaming data from various sources such as sensors or financial systems and also to perform Machine Learning tasks to derive special insights on the given data.

Now, Look at what Does Spark actually do?
Spark is capable of handling several petabytes of data at a time, distributed across a cluster of thousands of cooperating physical or virtual servers. It has an extensive set of developer libraries and APIs. Spark also supports a variety languages such as Java, Python, R, and Scala; this flexibility of spark makes it well-suited for a range of use-cases, currently spark is used in almost every industry which generates a huge amount of data that requires processing . Spark is often used alongside Hadoop’s data storage module, HDFS, but it can integrate equally well with other popular data storage subsystems such as HBase, Cassandra, MapR-DB, MongoDB and Amazon’s S3.
Spark uses in-memory computation to process its data, because of this, computation speed with in spark is nearly 100 times faster, than Hadoop MapReduce and about 10 times faster when it runs on disk.

Before we go any further, lets look at a brief History of spark
Spark is an open source project that has been built and is maintained by a thriving
and diverse community of developers. In 2009 Spark started off as a Research Project in the UC Berkeley RAD Lab, later known as AMPLab. The researchers of this lab were previously working on Hadoop Map‐Reduce, and inferred that MapReduce was inefficient for iterative and interactive jobs. Thus, came the advent of Spark, from the very beginning it was designed to be fast, for interactive queries and iterative algorithms, and to overcome the disadvantage of Hadoop MapReduce, bringing in ideas like, support for in-memory storage and an efficient fault recovery.
Research papers were published about Spark at academic conferences and soon after
its creation in 2009, it already proved 10–20× faster than MapReduce for certain jobs and hence more efficient.
Some of Spark’s first users were other groups inside UC Berkeley. In a very short
Period itself , many external organizations began using Spark.
In addition to UC Berkeley, major contributors to Spark include Databricks, Yahoo!, and Intel become major contributors to spark in addition to UC berkely
In 2011, the AMPLab started to develop higher-level components on Spark, such as
Shark (Hive on Spark)1 and Spark Streaming. These and other components are sometimes
referred to as the Berkeley Data Analytics Stack (BDAS).
Spark was first open sourced in March 2010, and was transferred to the Apache Software
Foundation in June 2013 and In 2014 apache spark becomes the top level software in Apache foundation.
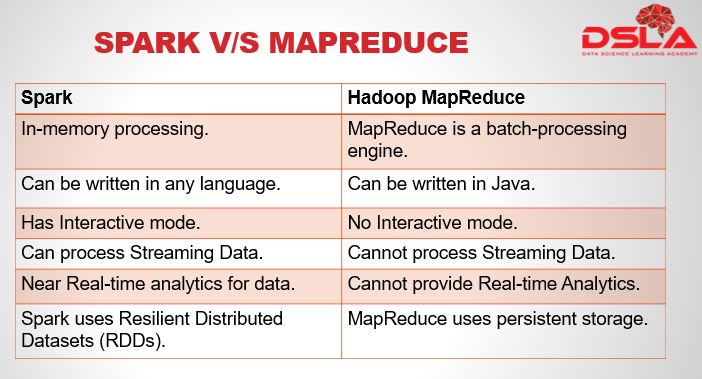
We have been saying till now that spark is very different from MapReduce. Now, Lets see how.
Spark uses In-memory processing of large Datasets, whereas, MapReduce is a batch-processing engine.
Spark is highly flexible and know for its ease of use. It can be written in any language like – Java, scala, python etc. MapReduce on the other hand is written in Java.
Spark has an interactive mode , MapReduce has No Interactive mode.
Spark is capable in processing Streaming Data. MapReduce Cannot process Streaming Data.
Spark’s in-memory processing delivers near real-time analytics for data. MapReduce was never designed for Real time Analytics
Spark uses Resilient Distributed Datasets (RDDs) and MapReduce uses persistent storage

Previously we have mentioned that spark can be used in almost any industry that generates and uses large quantities of data.
So now lets look at some use cases of spark.
1) Media & Entertainment:
Apache Spark is been used immensely in Media and Entertainment business, It has been proved to very impactful. One such sector in Media and Entertainment business is the The gaming industry, which uses spark to identify patterns from the real-time in-game events and to respond to them through auto adjustment of gaming levels based on complexity. This technology has proved to harvest lucrative business opportunities like targeted advertising, player retention and many more.
2) Finance Industry:
This industry uses Spark to access and analyze the social media profiles, call recordings, complaint logs, emails, forum discussions, etc. to gain insights which can help them make a right business decisions in regard with advertising and customer segmentation, it is also used for more serious concerns of security – like in credit risk assessment.
With the use of Apache Spark on Hadoop, financial institutions can detect fraudulent transactions in real-time, based on previous fraud footprints.
Next is E-commerce industry:
the Real time transactions occurring in E-commerce industries are being passed to Spark streaming algorithms to make proper informed decisions. E-commerce companies which are currently using spark, process over 30 million records in matter of minutes.
another industry that uses spark is Healthcare sector:
Apache Spark is already being used in healthcare industries to analyze patient records along with past clinical data, one such use is to identify which patients are likely to face health issues after being discharged from the clinic. It is also currently being used in genomic sequencing to reduce the time needed to process genome data.
last but not least is the Travel industry:
Many Leading travel websites are already using Apache Spark, they use the Machine learning tasks to give their cutomers a fast and personalized recommendations, which is based on users current and previous selection.
Mentioned here are few of the top sectors that uses spark.
Can you think few other such industries?