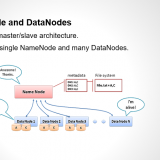
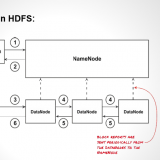
Hadoop File System and Operations

Hadoop has an abstract notion of filesystems, of which HDFS is just one implementation.
First we see local, now it’s a filesystem for a locally connected disk with client-side checksums.
Then hdfs i.e. Hadoop’s distributed filesystem which is designed to work efficiently in conjunction with MapReduce.
Next webhdfs, it is A filesystem which provides authenticated read/write access to HDFS over HTTP
Next Secure WebHDFS, it is the HTTPS version of WebHDFS. ftp, now it is a filesystem backed by an FTP server.
S3, is A filesystem backed by Amazon S3. Replaces the older s3n (S3 native) implementation. Lastly in our list Azure, which is A filesystem backed by Microsoft Azure.

We’re going to have a look at HDFS by interacting with it from the command line. There are many interfaces to HDFS, but the command line is one of the simplest and, to many developers, the most familiar. Here we would see few the commonly used hadoop commands.
In this slide we see commands to display the hadoop version. A command to List the contents of the root directory in HDFS. Another shows the command to find the amount of space used and available for the mounted Filesystem. In this slide our last command helps to find the no. of files and directories for a particular file. From these commands we can easily makout that the hadoop filesystem commands are very similar to unix commands.

Moving forward we see fsck command to run a dfs filesystem checking utility on the root director
Next we see how we can create a new directory named hadoop within hdfs using – mkdir command. Next we see 2 methods to copy file to the HDFS from the local directory, namely: “put” and “copyfromlocal” commands.

Similarily we have 2 commands to place the data to local folder from hdfs, for that we use we use – “get” & ”copytolocal”.
Next we see methods to delete/ remove the files from HDFS using –rm method. To recursively use delete on all the files of the folder we use –r method , this commad enables recursive operation on the folder.
Lastly we see –help method to find all the commands present hadoop file system. “-help” method.

Parallel Copying with dist-CP(distcp): the HDFS access patterns that we have seen so far focus on single-threaded access. To diversify our access, Hadoop comes up with a very useful tool called ‘dist-CP’ that is useful for copying data to and from Hadoop filesystems in parallel.
One use for distcp is as an efficient replacement for hadoop copy command.
You can copy one file or directory from one location to another easily using a single distcp, as shown in the below 2 examples.
File1 and dir1 are the input that needs to be copies and, file2 and dir2 are the output, If dir2 does not exist, it will be created automatically by the system, and the contents of the dir1 directory will be copied there. We are also able to specify multiple source paths, i.e. which all files will be copied to the destination. If dir2 already exists, then dir1 will be copied under it, creating the directory structure dir2/dir1.
We have an overwrite option with in distcp to keep the same directory structure and force files that are required to be overwritten. And also an update command which will update only those files that were changed.