Apache Spark Architecture
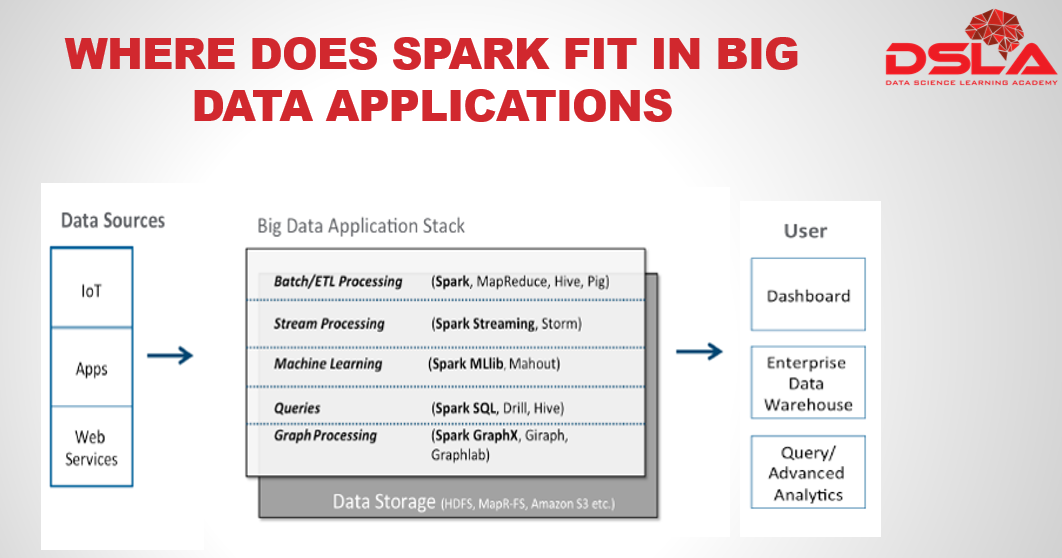
From the image shown above one can easily understand the huge dynamics of spark.
The section on the left hand side of the image depicts all the different sources which provides the input data that requires to be processed or its needed for analytical insights. Some of the common sources are IoT, data from apps, sensor data, social media, public media, Network and in-stream monitoring technologies, etc.
Next is the stack in the middle, which represents various Big Data processing workflows and tools that are commonly used. From this stack one can easily realize that Spark is one stop processing engine to satiate all your big data woes, as it has the ability to process the data in batch, in stream, create graph, and also perform machine learning analytics algorithm. You can easily have any one of these workflows in your application, or a combination of many.
Lastly we have the output stack, here we see that the processed dataset can then be used to create real-time dashboards and alerting systems for querying and for advanced analytics, or it can be used to load into an enterprise data warehouse.
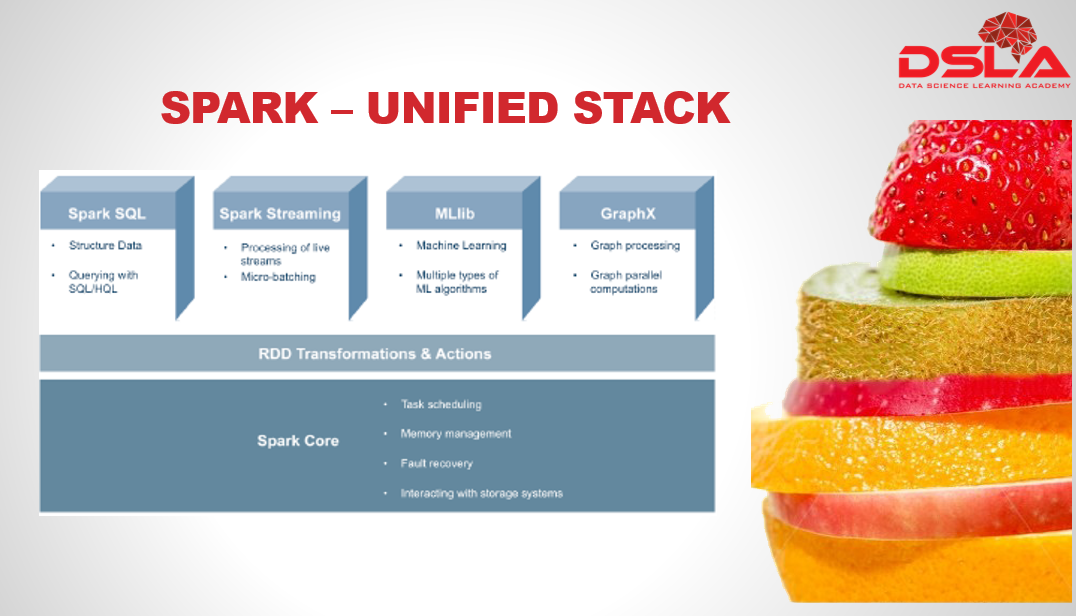
Spark is often known as a unified stack. From our previous slide we have received some idea as to why its said so.
Spark is developed in such a way that its integrated with various higher level components of different functionalities such as: Spark SQL, Spark streaming, M-lib and GraphX.
Before we get started with the higher level components lets first check out the core of spark and cluster manager options.
- Spark Core contains the basic functionality of Spark, which includes task scheduling, memory management, fault recovery, interacting with storage systems, and more. Spark Core is also home to the API that defines resilient distributed datasets (RDD), which are Spark’s main programming abstraction.
- A cluster manager is a pluggable component, which provides Spark with option to choose from a variety of different external cluster managers. The most popular cluster managers accessible by spark are YARN, Mesos, as well as the sparks built-in Standalone cluster manager ( we would see this in more details in later chapter – chapter 5)
Lets start with the unified Stack of spark :
- Spark SQL is the Spark’s interface for working with structured and semi-structured data. The data can be queried using SQL or HiveQL. Spark sql supports many types of data sources such as structured Hive tables and complex json data. When used within a Spark program, it provides rich integration between SQL and regular Python/Java/Scala code, including the ability to join r-d-dees and SQL tables, custom functions in SQL, etc. Many jobs are easier to write using this combination.
- Spark streaming is the spark module for processing of live streams of data and doing real-time analytics. For example, an application might track statistics about page views in real time, train a machine learning model, or automatically detect anomalies.
- Machine learning algorithms attempt to make predictions or decisions based on training data, often maximizing a mathematical objective about how the algorithm should behave. M-lib contains a variety of learning algorithms and is accessible from all of Spark’s programming languages.
- GraphX is a library with various operators for manipulating graphs and performing graph-parallel computations. It allows us to create a directed graph with arbitrary properties attached to each vertex and edge.
As against a common belief, Spark is not a modified version of Hadoop and is not, really, dependent on Hadoop because it has its own cluster management. Hadoop is just one of the ways to implement Spark.
It’s important to remember that Spark does not require Hadoop; it simply has support for storage systems implementing the Hadoop APIs.
Another point to remember is that spark does not have its own storage system or database, but its designed to work with any Hadoop external storage system.
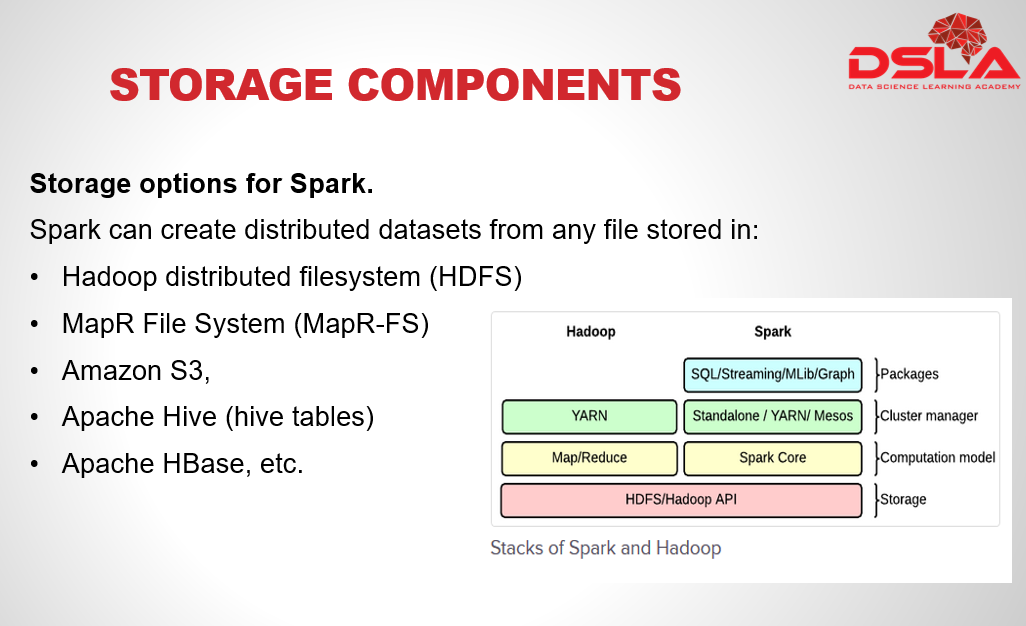
The components that are accessible through spark is HDFS, MapR-FS, Amazon S3, apache Cassandra, hive tables, hbase etc.

Spark can read data from any storage system in a no.of format and can send output to any of the storage unit like Local FS, HDFS in any of the Hadoop output format.
The file formats that are supported by Spark are given below:
Text , Sequence, avro, paraquet and other Hadoop input format.
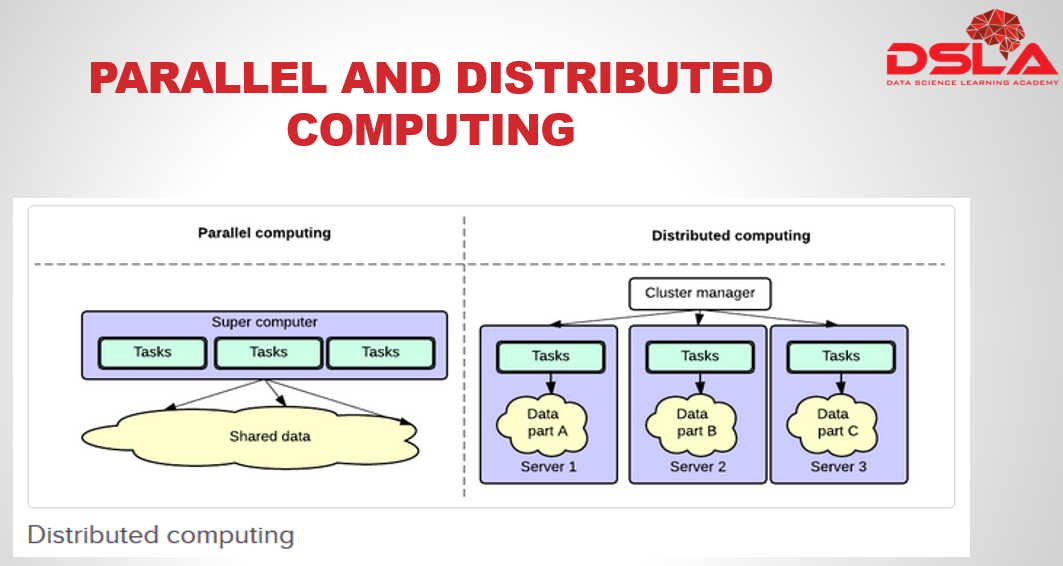
We have earlier mentioned that spark designed to run on a distributed framework. But before we go through its advantage lets first understand the difference between Parallel and distributed computing. In case of parallel computing, data is placed in a shared space where all tasks have access to the shared data to exchange information and perform their calculations. Where as with distributed computing, each task has its own data. Information is exchanged by passing data between the tasks.Finally the Advantages of using Distributed Computing .
data locality is one of the main concepts of distributed computing, data locality helps in reducing unwanted network traffic. Because of data locality, data is processed in a much faster and more efficient manner, as the data is present with in the same node and no data request or travelling is required. With distributed computing this is no separate storage network or processing network. Also, It is easily scalable, and one can simply build a cluster with commodity hardware.
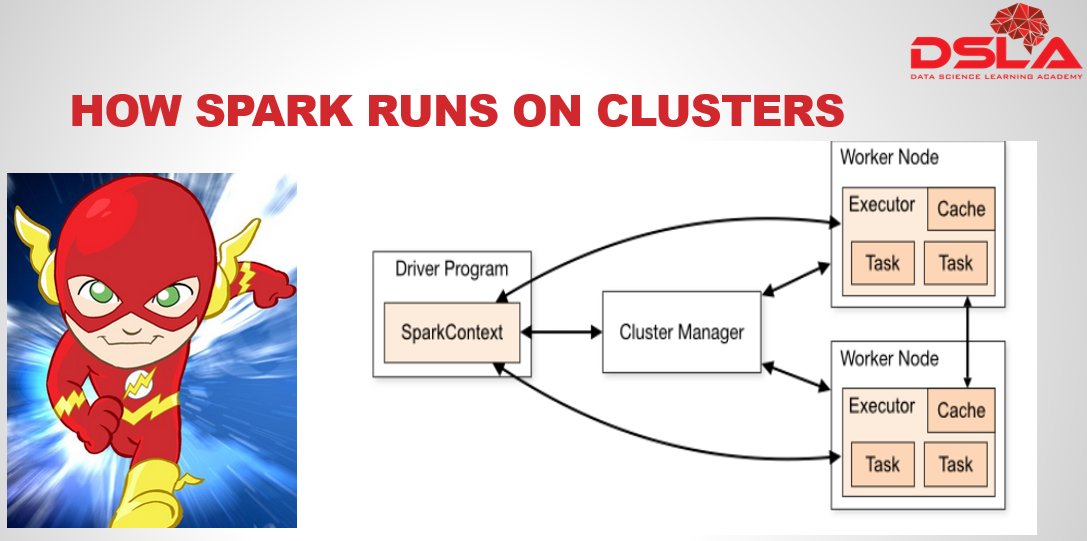
How Spark main runs in the cluster. (kindly go through the diagram to go through the process.
Spark applications run as independent sets of processes on a cluster, it is coordinated by the SparkContext object in your main program.
SparkContext is used to connect to Cluster via Cluster Manager.
Cluster Managers is a service that is used to acquire the resources. They are of several forms namely : Standalone, Yarn and Mesos.
Spark Executor : A process assigned for each application which runs applications and stores the data.
Job : Consists of multiple tasks launched in response to a Spark action.
Task : It is sent to executor by SparkContext.
Worker node : A node that executes application programs on it.

What happens when a Spark Job is submitted?
Steps after job submission:
1) User submits a job or application after using the command of spark-submit
2) The main() method specified by the user with in “spark-submit” is invoked. This method also launches the driver program.
3) Driver then implicitly converts the code into a logical Directed Acyclic Graph (DAG) with certain optimizations for example pipelining is one common optimization technique
4th Step,the driver converts the logical DAG into physical execution plan with set of stages. After that the Driver creates a small physical execution units referred called tasks under each stage. Then tasks are bundled together to be sent to the Spark Cluster.
4th Step,the driver converts the logical DAG into physical execution plan with set of stages. After that the Driver creates a small physical execution units referred called tasks under each stage. Then tasks are bundled together to be sent to the Spark Cluster.
- The driver program then talks to the cluster manager and negotiates for resources that would be needed to run the application.
- Next the tasks are then bundled together to be sent to the Spark Cluster.
- The cluster manager launches executors on the worker nodes on behalf of the driver.
- At this point the driver sends tasks to the cluster manager to get a holistic view of all the executors.
- Now executors start executing the various tasks assigned by the driver program.
- Lastly, When driver exists main () method or when it calls the stop () method of the Spark Context, it will terminate all the executors and release the resources from the cluster manager.