AWS Glue
AWS Glue Platform and Components
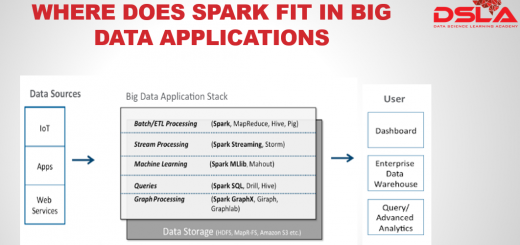
AWS Glue is built on top of Apache Spark, which provides the underlying engine to process data records and scale to provide high throughput, all of which is transparent to AWS Glue users.
The new service has three main components:
- Data Catalog—A common location for storing, accessing and managing metadata information such as databases, tables, schemas and partitions. Creating an ETL job to organize, cleanse, validate and transform the data in AWS Glue is a simple process. When setting up the connections for data sources, “intelligent” crawlers infer the schema/objects within these data sources and create the tables with metadata in AWS Glue Data Catalog.
- ETL Engine—Once the metadata is available in the catalog, data analysts can create an ETL job by selecting source and target data stores from the AWS Glue Data Catalog. It’s not necessary to know the target schema in advance as it will be provided by the catalog. The next step is to define an ETL job for AWS Glue to generate the required PySpark code. Developers can customize this code based on validation and transformation requirements.
- Scheduler—Once the ETL job is created, it can be scheduled to run on-demand, at a specific time or upon completion of another job. AWS Glue provides a flexible and robust scheduler that can even retry the failed jobs.
Benefits:
- Easy: AWS Glue automates much of the effort in building, maintaining, and running ETL jobs. AWS Glue crawls your data sources, identifies data formats, and suggests schemas and transformations. AWS Glue automatically generates the code to execute your data transformations and loading processes.
- Integrated: AWS Glue is integrated across a wide range of AWS services. AWS Glue natively supports data stored in Amazon Aurora, Amazon RDS for MySQL, Amazon RDS for Oracle, Amazon RDS for PostgreSQL, Amazon RDS for SQL Server, Amazon Redshift, and Amazon S3, as well as MySQL, Oracle, Microsoft SQL Server, and PostgreSQL databases in your Virtual Private Cloud (Amazon VPC) running on Amazon EC2. AWS Glue provides out-of-the-box integration with Amazon Athena, Amazon EMR, Amazon Redshift Spectrum, and any Apache Hive Metastore-compatible application.
- Serverless: AWS Glue is serverless. There is no infrastructure to provision or manage. AWS Glue handles provisioning, configuration, and scaling of the resources required to run your ETL jobs on a fully managed, scale-out Apache Spark environment. You pay only for the resources used while your jobs are running.
- Developer Friendly: AWS Glue generates ETL code that is customizable, reusable, and portable, using familiar technology – Scala, Python, and Apache Spark. You can also import custom readers, writers and transformations into your Glue ETL code. Since the code AWS Glue generates is based on open frameworks, there is no lock-in. You can use it anywhere.
How AWS Glue Works:
- Build your data catalog: First, use the AWS Management Console to register your data sources. AWS Glue will crawl your data sources and construct your Data Catalog using pre-built classifiers for many popular source formats and data types, including JSON, CSV, Parquet, and more.
- Generate and Edit Transformations: Next, select a data source and data target. AWS Glue will generate ETL code in Scala or Python to extract data from the source, transform the data to match the target schema, and load it into the target. You can edit, debug and test this code via the Console, in your favorite IDE, or any notebook.
- Schedule and Run Your Jobs: AWS Glue makes it easy to schedule recurring ETL jobs, chain multiple jobs together, or invoke jobs on-demand from other services like AWS Lambda. AWS Glue manages the dependencies between your jobs, automatically scales underlying resources, and retries jobs if they fail.
AWS Glue Use Cases:
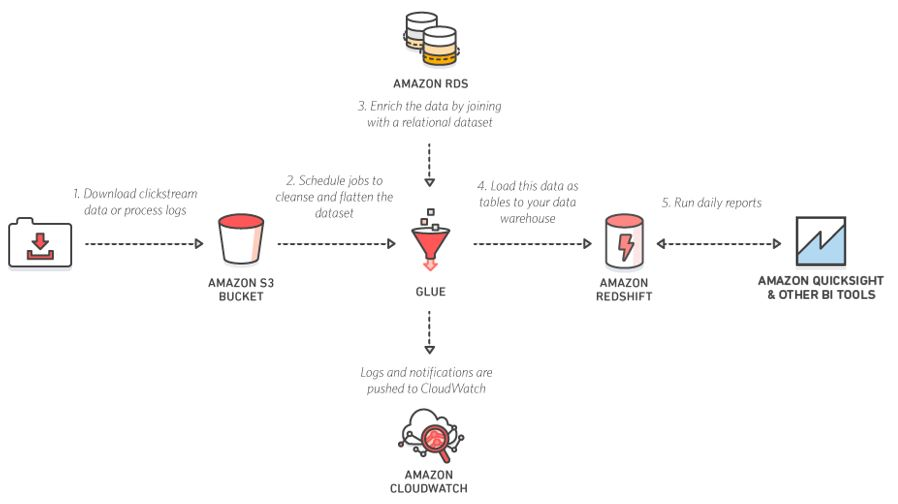
Analyze Log Data in Your Data Warehouse: Prepare your clickstream or process log data for analytics by cleaning, normalizing, and enriching your data sets using AWS Glue. AWS Glue generates the schema for your semi-structured data, creates ETL code to transform, flatten, and enrich your data, and loads your data warehouse on a recurring basis.
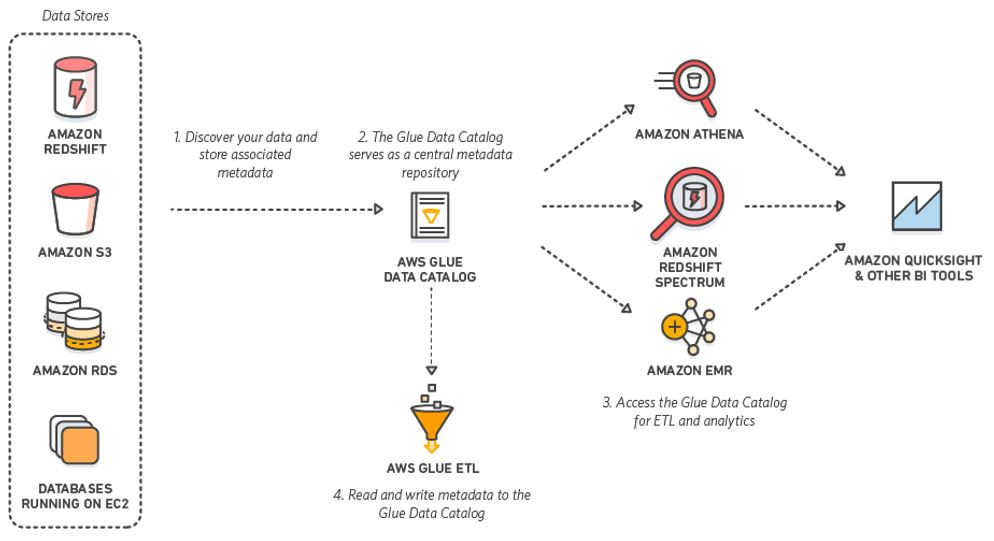
Unified View of Your Data Across Multiple Data Stores:
You can use the AWS Glue Data Catalog to quickly discover and search across multiple AWS data sets without moving the data. Once the data is cataloged, it is immediately available for search and query using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
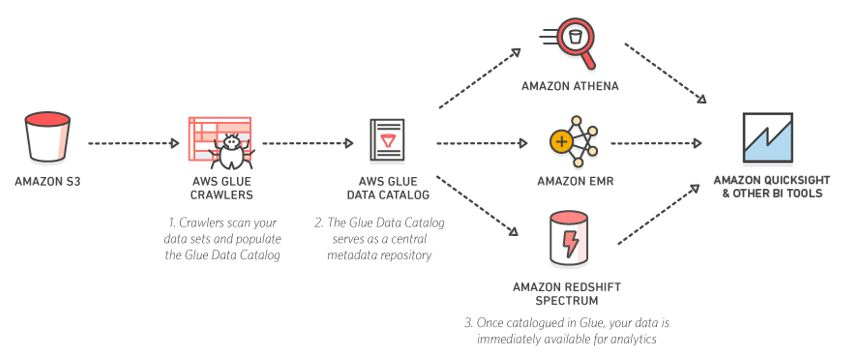
Queries Against an Amazon S3 Data Lake:
Data lakes are an increasingly popular way to store and analyze both structured and unstructured data. If you use an Amazon S3 data lake, AWS Glue can make all your data immediately available for analytics without moving the data. Glue crawlers can scan your data lake and keep the Glue Data Catalog in sync with the underlying data. You can then directly query your data lake with Amazon Athena and Amazon Redshift Spectrum. You can also use the Glue Data Catalog as your external Apache Hive Metastore for big data applications running on Amazon EMR.
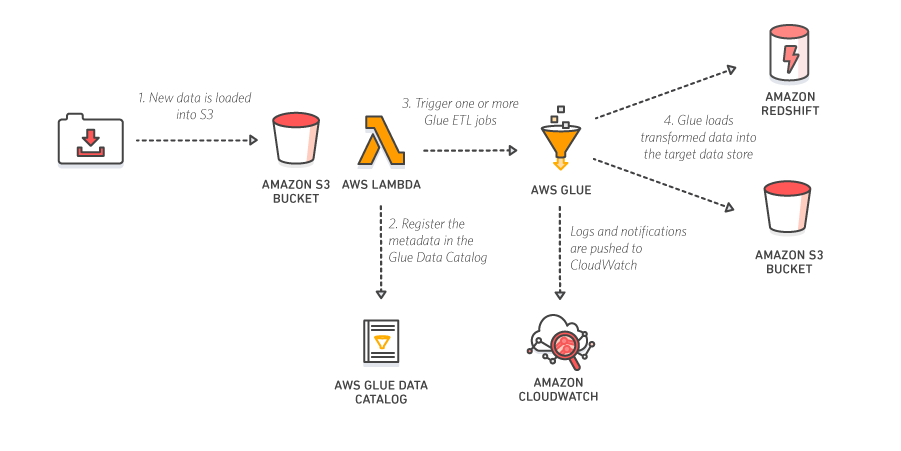
Event-driven ETL Pipelines:
AWS Glue can run your ETL jobs based on an event, such as getting a new data set. For example, you can use an AWS Lambda function to trigger your ETL jobs to run as soon as new data becomes available in Amazon S3. You can also register this new dataset in the AWS Glue Data Catalog as part of your ETL jobs.