Features of RDD & its Operations
Lets look at some of the more appealing features of apache spark and RDD.

Apache Spark performs in-memory computation, also it evaluates RDDs lazily i.e. they do not compute their results right away. Instead, they just remember the transformations applied to some base dataset, until an action is applied to them as per the requirement.
Lazy evaluation improves efficiency by incorporating optimization techniques automatically, such as pipelining, which in turn saves lots of time. RDD stores intermediate results in distributed memory – RAM, instead of stable storage like disks.
Data sharing across the network of nodes is considered safe as RDDs are immutable, meaning that once it has been created it cannot be manipulated, so every time an operation is performed on an RDD it results in a new RDD or simply creates a non rdd value that can be considered as final results. Hence, consistency is achieved through immutability.
RDDs are fault tolerant, as they are able to regenerate lost data using lineage information presented in Directed Acyclic graph.
Spark RDDs can be persisted. Users can identify which RDDs they would need to reuse over an over again, and choose an in-memory storage strategy for them, using persist() method.
RDD partitions the record logically and distributes the data across various nodes in the cluster. The logical divisions are in place for the processing purpose i.e. to ensure parallelism.
RDDs are capable of defining placement preference to compute partitions. Placement preference refers to information about the location of the RDD. The DAG scheduler places the partitions in such a way that task is close to data as much as possible. Thus speed up computation, this feature is referred to as Location-stickiness.
Spark RDDs are Coarse-grained, which means that we can apply an operation on dataset as a whole, but not on individual element with in the dataset.
Where do we need Spark RDD? Listed here are some of the main reasons behind the inception and creation of RDDs.
First being a faster processing need when it comes to Iterative algorithms and also for interactive data mining tools. If the above two cases make use of Sparks RDD, the data is cached in-memory, and all its computation takes place there itself, this improves performance and reduces time by an order of magnitude.
Next reason is DSM, Distributed Shared Memory, it is a very general abstraction, but this generality makes it harder to implement in an efficient and fault tolerant manner on commodity clusters. Hence, the need of sparks RDD.
Lastly, in distributed computing system data is stored in intermediate stable distributed platform such a hdfs or Amazon S3. This makes the computation of job slower since it involves many IO operations, replications, and serializations in the process. Hence the need to implement RDD.

RDDs support two types of operations: one is transformations and other actions. Transformations are operations that takes an RDD as input and returns one or more new RDDs. Transformation are lazy and ensures internal optimization, one such example is Pipelining the functions. Examples of transformation includes map(), distinct and filter(). Actions, Actions are operations that trigger execution of the RDD, starting from the very first step. Actions produce a non-RDD value. Examples of Action are count(), take() and first(). Spark treats transformations and actions very differently, so understanding which type of operation you are performing will be important. If you are ever confused whether a given function is a transformation or an action, you can look at its return type.
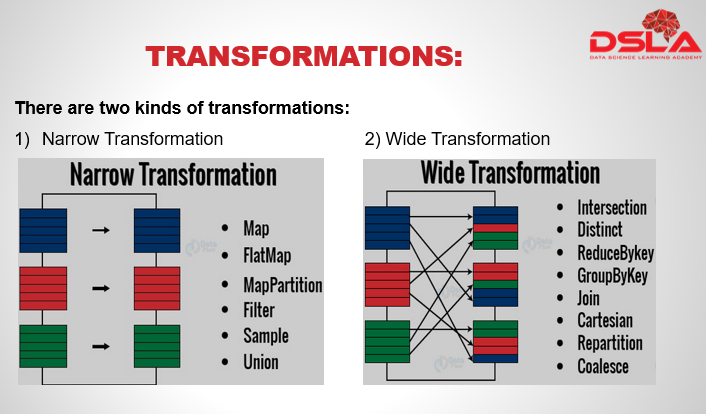
When an output RDD can be created by taking only 1 partition of the Dataset its called narrow transformation, example functions include : Map, Flatmap, filter. These functions require – 1 input partition and an operatory function. Wide Transformation: When 2 or more than 2 dataset partitions are required to compute an output RDD. Examples – join, intersection, etc : these are called wide transformation.
Actions are operations that force the evaluation of an RDD by triggering transformation function. It loads the data into original RDD, carry out all intermediate transformations and return final results, a non RDD value, to Driver program or write it out to file system. Actions use lineage graph information to perform all the transformation functions of a particular RDD, to maintain sequence of order. Commonly used Actions are namely .. Count , reduce, collect, take, first etc
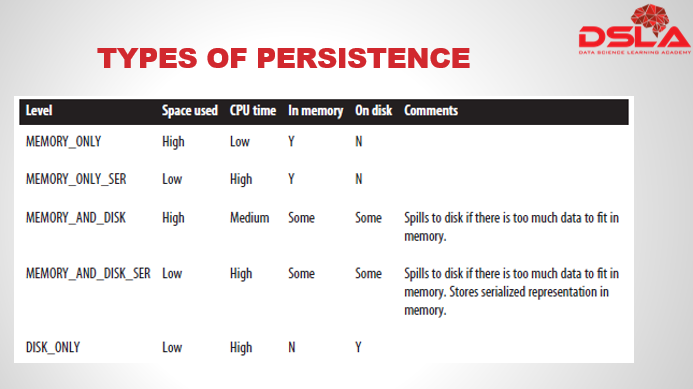
Types of Persistence available are as follows:
- Memory_only: Stores data as it is in memory. Hence uses lots of space.
- Memory_only_ser: Stores data after converting it to serializable data in memory . Serializable data uses less of space but more CPU time is spend in conversion.
- Memory_and_disk: Stores data as it is in memory and on Disk, only if there is a lot of data.
- Memory_and_disk_ser: Stores data after converting it to serializable data in memory and on disk.
- Disk_only: This stores the entire data as it is to Disk. Hence, zero memory utilized, but takes lots of time to compute.
- Spark continuously monitors cached data on each node.
- If one attempts to cache too much data, Spark will automatically remove old partitions using a Least Recently Used (LRU) cache policy.
- This is done to create space for new dataset.
- RDDs provide a method called unpersist() which helps to manually remove the persisted RDD.