What is Apache Spark?
Apache Spark is a powerful open source processing engine, with a cluster computing framework. Spark is designed in such a way to ensure lightening fast data processing of large datasets. this includes Batch processing...
Transforming Business
Apache Spark is a powerful open source processing engine, with a cluster computing framework. Spark is designed in such a way to ensure lightening fast data processing of large datasets. this includes Batch processing...
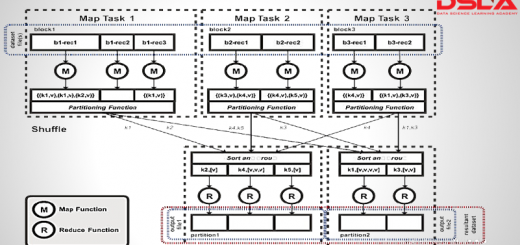
To begin, lets start with the most basic question of what is hadoops Mapreduce? MapReduce is a Simple programming model for data processing. MapReduce is an inherently parallel processing unit. Which essentially consists of...
Big Data Developer – Most Exciting IT Job of the Century This century marks a new era, an era of Data. The data today is growing stupendously with each passing second. Hence, the role...
In an ideal world, the requests that a YARN application makes would be granted immediately. In the real world, however, resources are limited, and on a busy cluster, an application will often need to...
Major Difference between map reduce 1 and mapreduce2 i.e YARN. In MapReduce 1, there are two types of daemon that control the job execution process: a jobtracker and one or more tasktrackers. The jobtracker...
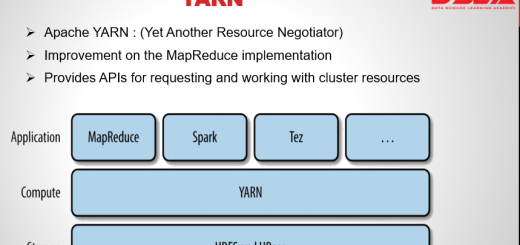
Apache YARN introduction: it is short for Yet Another Resource Negotiator. As the name indicates it is a Hadoop’s cluster resource management system. YARN was introduced in Hadoop version 2 to improve the MapReduce...
A Data Scientist is someone who makes information or valuable insights out of data. To understand what a data scientist is, what they do and more about them lets begin with understanding; what data...
Hadoop has an abstract notion of filesystems, of which HDFS is just one implementation. First we see local, now it’s a filesystem for a locally connected disk with client-side checksums. Then hdfs i.e. Hadoop’s...
Failover and Fencing: are 2 very important properties of HDFS, which aims to provide an overall efficiency of the eco-system. The transition from the active namenode to the standby is managed by a new...
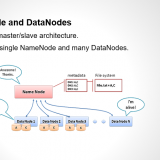
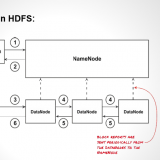
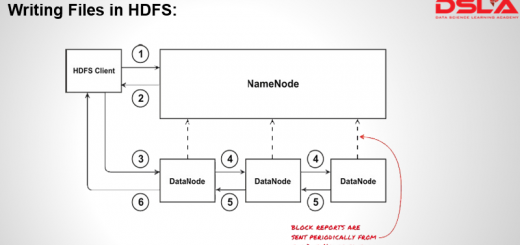
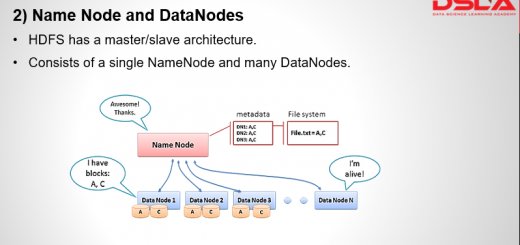
HDFS works upon a master-slave architecture, where It consists of a single NameNode, referred as master node and many DataNodes, referred as slave nodes. Master node consists of all the meta information of the...

Analytics Translator / Artificial Intelligence / Big Data / Data Science
12 Sep, 2018