What is Hadoop?
What is Hadoop ?
what is Hadoop ? Hadoop is a complete eco-system of open source framework from Apache . It is used to store, process and analyze data which are very huge in volume.

Hadoop is written in Java and is not OLAP (online analytical processing). It is used for batch/offline processing and being used by Facebook, Yahoo, Google, Twitter, LinkedIn and many more. Moreover it can be scaled up and down by just adding or removing nodes in the cluster, as per need.
Modules :
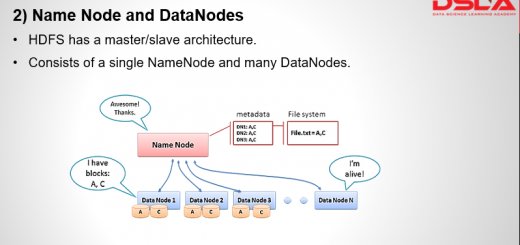
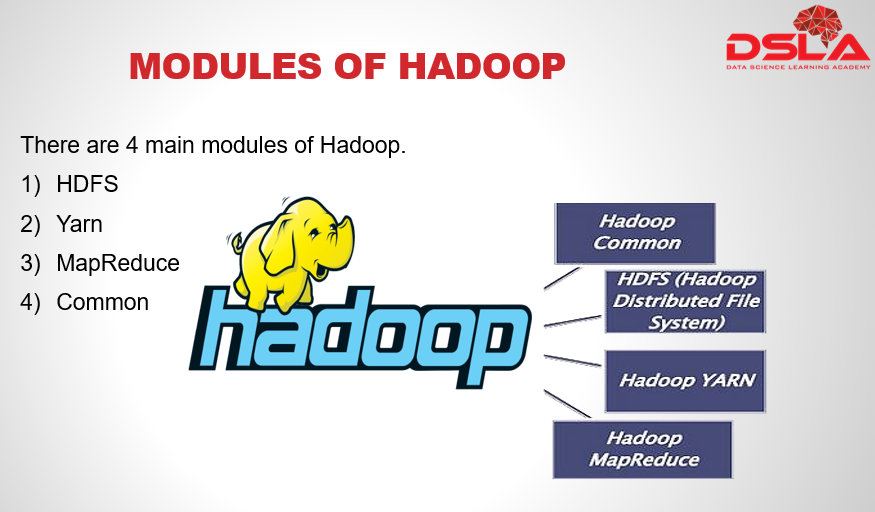
There are 4 major modules in Hadoop. Namely : HDFS, yarn, MapReduce and Common. first, is HDFS (Hadoop distributed File System) for storage, that allows to store data in a small memory block and distributes them across the cluster.
second is YARN, which stands for yet another resource negotiator, it is nothing but a processing unit of Hadoop, which also allocates resources that’s needed for processing task.
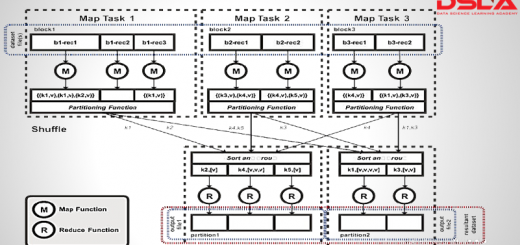
Thirdly Hadoop MapReduce – It is a java framework which executes tasks in a parallel manner by distributing it as small blocks across the cluster. the computation takes place in key value pair.
Lastly Common, it is a set of common utilities and libraries which handle other Hadoop modules. It makes sure that the hardware failures are managed by its cluster automatically.

Features:
Hadoop was the first technology designed in entirety to handle and manage magnanimous amount of data. There are quite few advantageous features of using Hadoop.
1) It is fast,. it is considered to be very fast as compared to the existing traditional system. In HDFS the data is distributed across the cluster and are mapped which helps in faster retrieval. Even the tools to process the data are often on the same servers, thus reducing the processing time.
2) It is Scalable: Hadoop cluster are scalable, meaning the cluster size can be increased or decreased as per requirement by just adding or removing nodes of the cluster any time we want.
3) It is Cost Effective: it is open source and uses commodity hardware to store data so it really is cost effective as compared to traditional relational database management system.
4) It is Resilient to failure: HDFS has the property with which it can replicate data over the network, so if one node is down or some other network failure happens, then it takes the other copy of data and use it. By default, data are replicated thrice but the replication factor is configurable.